Mimir - Real-time internet context for claims

01 Intro
This project was a follow up to our work on Unreally. Vincent and I wanted to build a new fact-checking method using state-of-the-art technologies like LangChain and the OpenAI davinci-003 model.
Our objectives:
- Extract the key claims of a given text
- Find relevant internet context and display it in natural language
- Integrate everything in a web-app
02 Design 📝
For the first objective, we are using TextRank + Bert. TextRank is a graph-based algorithm that performs extrative summarization, meaning is boils down a given text to its most important words or sentences without paraphrasing or altering them.
While this gives us the key sentences of the text, we still need a way to determine which of these are actually claims. This is done by using the BERT ClaimBusters model from Huggingface, which classifies each sentence from the summarization as claim or non-claim, leaving us with a list of the top-k key claims.
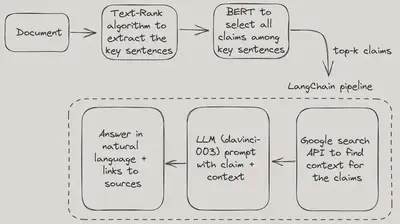
All of this is passed into a LangChain pipeline. First we use the integrated Google search API to find relevant web context for these claims and then scrape the text. The texts and the claims are used to prompt davinci to determine whether the context agrees with the claims or not. We use prompt enigneering techniques to achieve a neutral answer that includes both pros and cons:
# 💡 Info: We use few-shot prompting, meaning we give examples first
prompt = f"""
claim: Exercise is good for mental health.
context: Research studies have consistently shown that physical exercise can help reduce symptoms of anxiety and depression.
answer: The found context agrees with the claim, since exercise can help reduce symptoms of anxiety.
claim: Video games are a waste of time.
context: Many people enjoy playing video games as a form of entertainment and social interaction. However, videogames are linked to procrastination.
answer: The found context partially agrees with the claim, since some people enjoy videogames but it might lead to procrastination.
claim: {query}
Provide an Answer to the last given claim as demonstrated in the above examples and based on the context below.
"""
# 💡 Info: The internet context will be appended below to the prompt
This leads to differentiated answers, e.g. for the claim “Running is bad for your health” :
While running can be beneficial to your health, too much running can lead to chronic injuries, abnormal heartbeats and other health risks.
Finally, the answer and all the sources used for context are displayed in an UI. We’ve designed it to be clean and minimal in Figma and then implemented everything as a web-app using Pythons Flask library. You have the option to either upload a document or get context for a single claim. Once the orange button is pressed, the program will start.

Closing Thoughts 💭
There are multiple use cases for a system that gathers and interprets internet context in real-time:
- When training other machine learning models, this system could augment text data
- Automated fact-checking like we did with Unreally often requires the latest relevant news to work in production
- It can be integrated into other application to improve the users text understanding (e.g. for education or scientific research)
While our LangChain system already works well for these use cases, there are some parts of the pipeline which need improvement. In particular, the claim-extraction with TextRank + BERT has a lot of false positives. This means that the model classifies most sentences as claims, which is unsurprising because what exactly is a claim anyways? A way to narrow down the criteria for claims could be to only focus on political and economic claims by fine-tuning the model further in the future.
CASCODES
Hi, I’m a student and programmer interested in science and philosophy. Currently focusing on ML and NLP.