Kiyo - AI summarization browser extension

01 Intro
Huggingface BERT/Transformers is a hot topic in the machine learning world because it offers state of the art language processing for everyone.
For this project I wanted to use these technologies to build something that could be useful in everyday life. Since I’ve been reading a lot of papers and articles online, a summarization browser extension came to mind.
The main idea is:
- You highlight a few paragraphs of text in your browser and click on a “go” button in the extension
- Then the extension reads this text and sends it to a Python API
- The API uses a Transformers machine learning model to summarize the text and returns the result.
02 Design 📝
Essentially, project consists of three parts: The browser extension (Frontend), the API (backend) and the machine learning.
Frontend
In contrast to what I initally thought, the frontend was the most time consuming part of this project. The main reason for this is the way chrome extensions need to be structured. Every chrome extension requires three JS files:
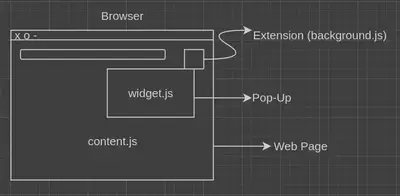
- The extension is the little icon that appears in the top row of the browser. It uses the
background.js - The pop-up gets opened by clicking on the extension icon. It includes
widget.html,widget.cssandwidget.js - The content of the web page itself can be accessed through the
content.js
Therefore the directory structure looks like this:
.
├── manifest.json --> required by chrome to define versions etc
├── res --> images
├── script
│ ├── background.js
│ ├── content.js
│ └── widget.js
├── style
│ ├── icons --> images for UI
│ └── style.css
├── summary.html -->popup page for displaying the text
└── widget.html -->main popup page
For the UI (Widget), I ended up with this: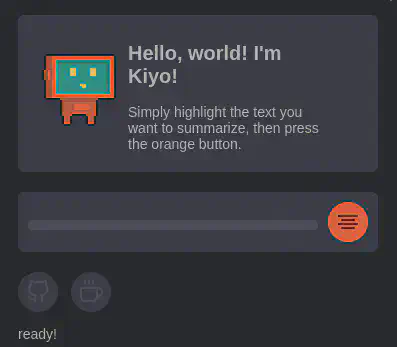
Because all three scipts only “see” a limited part of the browser, they need to communicate with each other in order to get the job done: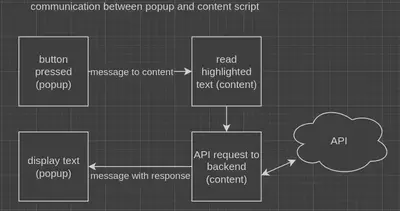
The communication between these scripts uses the build-in Chrome-API. One script sends a message, the other script listens for it and revieves it:
// sending a message with the chrome API
chrome.runtime.sendMessage({message: message});
// recieving a message
chrome.runtime.onMessage.addListener(
function(request, sendResponse) {
var text = request.message
sendResponse({message: "OK"}) // response to sender
// do stuff with the text of the message
}
);
Getting CORS (cross-origin resource sharing) down was the main problem, because it requires configuring both the client- and server side. For the client side I ended up with this function, which takes as input the text highlighted and uses the fetch API to send an async request to the backend.
function requestAPI(text) {
// send the request
var data = {"text": text}
var url = new URL(API_URL)
fetch(url, {
mode: "cors",
method: "POST",
body: JSON.stringify(data),
headers: {
'Content-Type': 'application/json',
// i've configured the token to limit the requests/sec for security
'x-api-key': TOKEN
}
}) // once the request resolves, we want to read the response
.then(response => response.json())
.then(rb => {
// send text to widget
console.log(rb);
sendMessage(rb);
});
}
Backend
I knew right from the beginning that I wanted to use Python for the API server. Python has a vast amount of machine learning libraries and some solid API frameworks. For the first draft, I used Flask to build an API server, but this turned out to be unnessecary because API Gateway does all the work. (more on that later)
Machine Learning
To keep it simple, I went with a Huggingface pretrained model. They can be imported into python easily and offer state of the art performance. Using the summarization pipeline is as easy as that:
from transformers import pipeline
# downloads the pipeline
def initalize_model():
pl = pipeline('summarization', model='ainize/bart-base-cnn')
return pl
# when called, summarizes the text and returns the result
def compute_summarize(text, pl):
summary = pl(text, min_length=30, do_sample=False)
return summary[0]
Instead of paraphrasing, bart-base-cnn weights the importance of each sentence, which makes it faster than some of the alternatives. Therefore, the result is a selection of sentences from the original text.
With that, the machine learning was done aswell! ✅
03 Deployment 🚀
After trying out different hosting methods, I’ve settled for AWS.
- Huggingface has great Sagemaker support
- Lambda functions are more cost efficient than a full-fledged server
- I’ve never worked with AWS and wanted to learn something new
The final pipeline looks like this: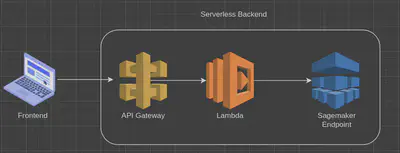
The requestAPI() method in content.js sends a POST request to API Gateway. API Gateway basically is a server that can be freely configured to invokes various AWS services, so I didn’t even need my Flask API server.
API Gateway then invokes a Lambda function, passing the JSON of the request. It reads the text, passes it into the sagemaker endpoint and returns the summarized text as a JSON response.
The machine learning takes about 5 seconds and the entire process takes up to 10 seconds, which can feel like a long time when waiting for something to load in a browser.
Still I have to admit that hosting an entire machine learning API on the cloud feels pretty cool.
👉 Check it out
Closing Thoughts 💭
In this project I’ve learned a lot about web development (like async requests and JSON), as well as deploying web applications and machine learning models on AWS.
The different AWS services and design patterns are really interesting and I definitely want to dive deeper into this topic in the future.
CASCODES
Hi, I’m a student and programmer interested in science and philosophy. Currently focusing on ML and NLP.